前言
本篇汲取了本书中较为精华的知识要点和实践经验加上读者整理,作为本系列里的第三篇章:异常与日志篇。
本系列目录:
- 《码出高效》系列笔记(一):面向对象中的类
- 《码出高效》系列笔记(一):面向对象中的方法
- 《码出高效》系列笔记(一):面向对象中的其他知识点
- 《码出高效》系列笔记(二):代码风格
- 《码出高效》系列笔记(三):异常与日志
- 《码出高效》系列笔记(四):数据结构与集合的框架
- 《码出高效》系列笔记(四):数据结构与集合的数组和泛型
- 《码出高效》系列笔记(四):元素的比较
- 走进JVM之内部布局
- 走进JVM之字节码与类加载
- 走进JVM之GC
异常
处理异常程序时,需要解决以下3个问题:
- 哪里发生异常
- 谁来处理异常
- 如何处理异常
无论采用哪种方式处理异常,都严禁捕获异常后什么都不做或打印一行日志了事。
学会对任何事情提出质疑;思考问题相比之前会更加多维度的切入;工作上做一件事会考虑它的责任划分、职能问题、;更加谨慎了(也不知道是好是坏)
异常分类
JDK中定义了一套完整的异常机制,所有异常都是Throwable的子类,分为Error(致命异常)和Exception(非致命异常)。其中Exception又分为checked(受检型异常)和unchecked(非受检型异常)。
checked异常与unchecked异常
checked异常是需要在代码中显示处理的异常,否则会编译出错。
- 力所能及、坦然处置型。如发生未授权异常(UnAuthorizedException),程序可以跳转至权限申请页面。
unchecked异常是运行时异常,它们是都继承自RuntimeException,不需要程序进行显式的捕捉和处理,该类异常可以分为以下3类:
- 可预测型异常(Predicted Exception):常见的大家都很熟悉包括IndexOutOfBoundsException、NullPointException等,此类异常不应该产生或者抛出,而应该提前做好边界检查、空指针判断处理等。显式的声明很蠢。
- 需捕捉异常(Caution Exception):例如在使用Dubbo框架在进行RPC调用时产生的远程服务超时异常DubboTimeoutException,此类异常是客户端必须显示处理的异常,不应该出现因产生该异常而导致不可用的情况,一般处理方法是重试或者降级处理。
- 可透出异常(Ignored Exception):主要是指框架或系统产生的且会自动处理的异常,而程序无需关心。例如Spring框架中抛出的NoSuchRequestHandlingMethodException异常,Spring框架会自己完成异常的处理,默认将自身抛出的异常自动映射到合适的状态码,比如启动防护机制跳转到404页面。
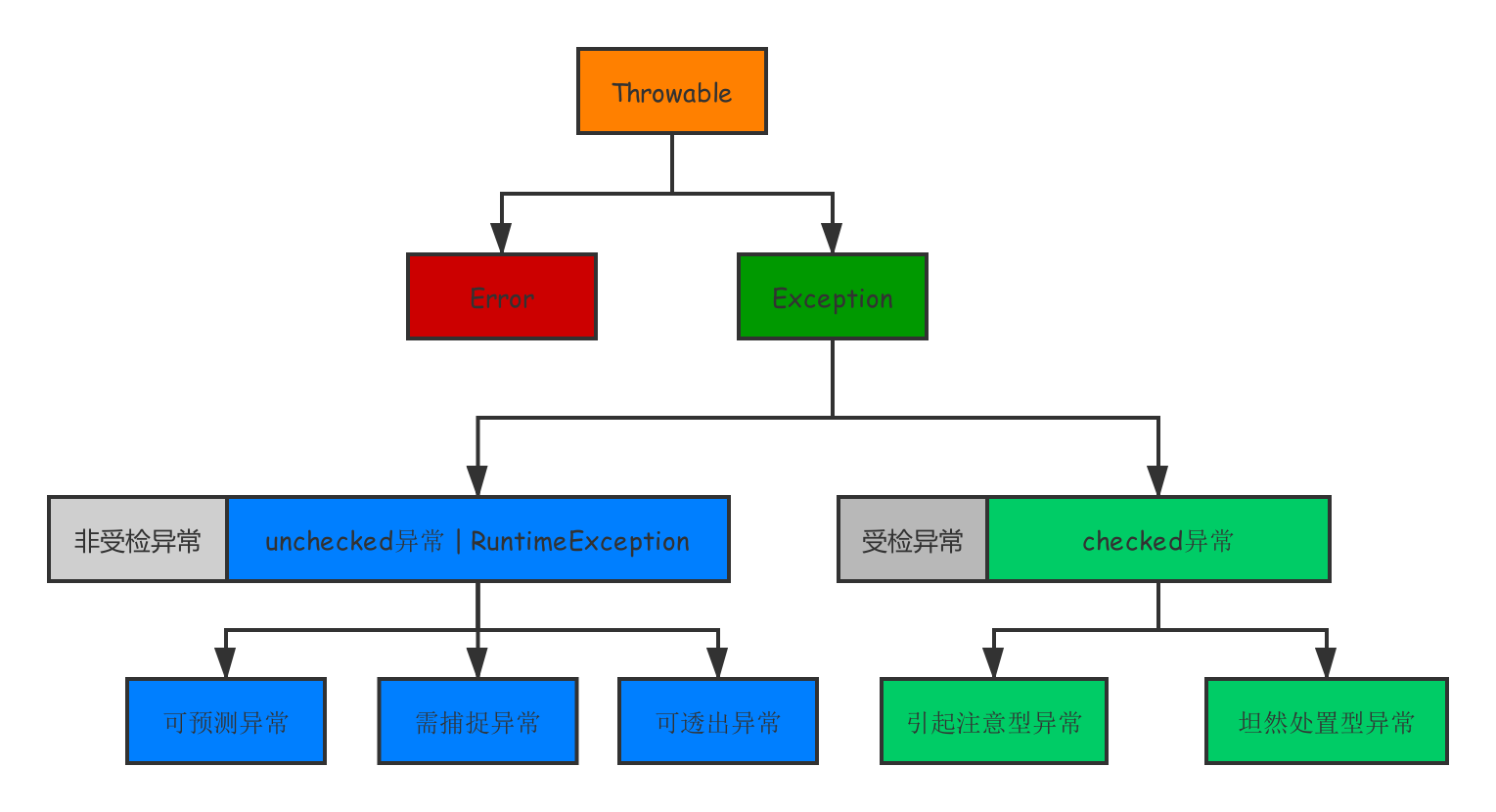
针对上图的结构,下面结合旅行的实例来说明一下异常分类。
第一,机场地震,属于不可抗力,对应异常分类中的Error。平时在出行时无需考虑该因素。
第二,堵车属于checked异常,应对这种异常,我们可以提前出发,或者改签机票。而飞机延误异常,虽然也需要check,但是我们无能为力,只能持续关注航班动态。
第三,忘带护照,可提前预测的异常,在出发前检查避免。去机场路上厕纸抛锚,突发异常难以预料,但是必须处理,属于需要捕获的异常,可以通过更换交通工具应对。检票机器故障属于可透出型异常,交由航空公司处理,我们无须关心。
try代码块
try-catch-finally是处理程序异常的三部曲。当存在try时,可以只有catch代码块,也可以只有finally代码块,就是不能单独只有try这个光杆司令。
- try代码块:监视代码执行过程,一旦发现发现异常则直接跳转至catch,如果没有catch,则直接跳转至finally。
- catch代码块:可选执行的代码块,如果没有异常发生则不会执行;如果发现异常则进行处理或向上抛出。这一切都在catch代码块中执行。
- finally代码块:必选执行的代码块,不管是否有异常产生,即使发生OutOfMemoryError也会执行,通常用于处理善后清理工作。如果finally代码块没有执行,那么有三种可能:
- 没有进入try代码块
- 进入try代码块,但是代码运行中出现了死循环或死锁状态
- 进入try代码块,但是执行了System.exit()操作
和return的关系
finally是在return表达式运行后执行的,此时将要return的结果已经被暂存起来,待finally代码块执行结束后再将之前的暂存的结果返回。
打印的结果:
1 | value = 101 |
以上的结果说明:
- 最后return的动作是由finally代码块中的
return ++z完成的,所以方法返回的结果101。 - 语句
return ++x中的++x被成功执行,所以运行结果是2。 - 如果有异常抛出,那么运行结果将会是y=11,而x=1。
finally代码块中使用return语句,使返回值的判断变得复杂,所以避免返回值不可控,我们不要在finally代码块中使用return语句。
try与锁的关系
lock方法可能会抛出unchecked异常,如果放在try中,必然触发finally中的unlock方法执行。对未加锁的对象解锁会抛出unchecked异常。所以在try代码块之前调用lock方法,避免由于加锁失败导致finally调用unlock抛出异常。
1 | Lock lock = new XxxLock(); |
所以在try代码块之前调用lock方法,避免由于加锁失败导致finally调用unlock方法抛出异常。lock.lock();这段代码应该移到try的上方。
异常的抛与接
- 对外提供的开放接口,使用错误码;
- 公司内部跨应用远程服务调用优先考虑使用Result对象来封装错误码、错误描述、栈信息;
- 应用内部者推荐直接抛出异常对象。
个人习惯:无论是否自定义了异常类或者 handle,都应该做两点:根据实际情况选择是否输出、保留原始栈信息;向上转型成分类好的错误码和简要描述。
日志
日志有什么用就不用多说了吧
日志规范
推荐的日志的命名方式:appName_logType_logName.log,其中logType位日志类型,推荐分类有status、monitor、visit等,logName为日志描述。
日志的保存至少在15天,当然还是以实际情况为准。
日志的级别由低到高排序:
- DEBUG:记录对调试程序有帮助的信息。
- INFO:记录程序运行现场,一般作用于对其他错误的指导意义。
- WARN:也可记录程序运行现场,但是更偏向于表明此处有出现潜在错误的可能。
- ERROR:表明此处发生了错误,需要被关注,但是当前发生的错误,并未影响系统的运行。
- FATAL:表明当前程序运行出现了严重的错误事件,并且将会导致应用程序中断。
不同的级别,要有不同的处理方式。
预先判断日志的级别
使用占位符的形式打印,避免字符串的拼接输出信息1
logger.info("id = {} and symbol = {}", id, symbol);
避免无效日志打印
生产环境禁止DEBUG日志打印且有选择的输出INFO日志。
避免重复打印,设置additivity=false,示例如下:1
<logger name = "com.xxx.xxx.config" additivity="false">
区别对待错误日志
一般设定ERROR级别的日志需要人为介入保证记录内容完整
- 记录异常时一定要输出异常堆栈,例如
logger.error("xxx" + e.getMessage(), e);。 - 日志中如果输出对象实例,要确保实例类重写了toString方法,否则只会输出对象的hashCode的值,没有实际意义。
- 记录异常时一定要输出异常堆栈,例如
日志框架
现在ELK也非常流行,功能比较强大。
日志门面
门面设计模式是面向对象设计模式中的一种,类似JDBC的概念。提供一套接口规范,本身不具备实现,目的是让使用者不用关注底层是哪个日志库。最广泛的有两种:slf4j和commons-logging。日志库
它是具体实现日志的相关功能,主流有三个,分别是log4j、log-jdk、logback。logback最晚出现,和log4j是同一个作者,是它的升级版并且本身就实现了slf4j的接口。
业界标准门面模式:slf4j+logback组合。
日志打印规范如下
1 | private static final Logger logger = LoggerFactory.getLogger(Xxx.class); |
logger被定义为static变量,是因为与当前的类绑定,避免每次都new一个新的对象,造成资源浪费,甚至引发OOM问题。
另外注意日志库冲突。例如:页面出现500错误,但是整个系统中未发现任务异常日志。由于是log4j作为当前日志库,但是间接地引入了logback日志库,导致打印日志的logger引用实际指向ch.qos.logback.classic.Logger对象,冲突导致日志打印失效。