前言
本篇汲取了本书中较为精华的知识要点和实践经验加上读者整理,作为本系列里的第一篇章第三节:面向对象的其他知识点篇。
本系列目录:
- 《码出高效》系列笔记(一):面向对象中的类
- 《码出高效》系列笔记(一):面向对象中的方法
- 《码出高效》系列笔记(一):面向对象中的其他知识点
- 《码出高效》系列笔记(二):代码风格
- 《码出高效》系列笔记(三):异常与日志
- 《码出高效》系列笔记(四):数据结构与集合的框架
- 《码出高效》系列笔记(四):数据结构与集合的数组和泛型
- 《码出高效》系列笔记(四):元素的比较
- 走进JVM之内部布局
- 走进JVM之字节码与类加载
- 走进JVM之GC
同步与异步
同步调用是刚性调用,是阻塞式操作,必须等待调用方法体执行结束。而异步调用是柔性调用,是非阻塞式操作。
举个与我们息息相关的例子,git代码提交托管时,提交代码的操作是同步调用,需要实时返回给用户结果,但是当前库代码相关活动就不是时间敏感的,在提交代码时,发送一个消息到后台的缓存队列中,后台服务器定时消费这些消息即可。
覆写
覆写是多态的一中表现,大部分人可能把它称为重写,我也遵循了本书的命名,重写可能暗示了推倒重来的过程,而覆写则更多的表达出重写一部分而覆盖。出现覆写的情况非常的多,POJO类toString()方法的覆写,工厂模式的抽象工厂类调用具体工厂子类的方法。通常这也被称作向上转型:
1 | Father father = new Son(); |
向上转型时,通过父类应用执行子类方法时需要注意以下两点:
- 无法调用到子类中存在而父类本身不存在的方法。
- 可以调用到子类中覆写了父类的方法,这是一种多态实现。
成功覆写父类方法,满足以下4个条件:
- 访问权限不能变小。具体表现为父类中public的方法,在子类继承覆写该方法时变成了private,则破坏了封装,编译也不会通过,所以不允许将访问权限缩小:
1 | class Father { |
- 返回类型能够向上转型称为父类的返回类型。
- 异常也要能向上转型成为父类的异常。unchecked异常(空指针异常这些)不需要显式的向上抛出,但是checked异常只能抛出异常或者此异常的子类。
- 方法名和参数类型以及个数必须严格一致。所以建议添加一个
@Override注解,编译器会自动检查覆写方法签名是否一致。防止出现明明是要覆写该方法变成新的方法。@Override还可以避免控制权限修饰符可见范围引发的问题,比如Father类中的A方法,是无权限修饰符,Son类继承Father类但是不在一个包下,Son类直接覆写A方法,若是没有加上@Override注解,可能会被编译器认为是一个新的方法。
总结成口诀:「一大两小两同」。
- 一大:之类的方法访问权限控制符只能相同或者变大。
- 两小:抛出的异常和返回值只能变小,可以转型成父类对象。子类的返回值、抛出异常类型必须与父类的返回值、抛出异常类型存在继承关系。
- 两同:方法名和参数必须相同。
另外注意:子类和父类不要相互调用彼此的方法,不然会变成循环调用,最后直至JVM崩溃,产生StackOverflowError异常。
重载
在同一个类中,如果多个方法有相同的方法名、不同的参数,即称为重载,比如一个POJO类中多个构造方法。以及String类中的valueOf,它有9个方法,可以将输入的基本数据类型、数组、Object等转化成为字符串。
我们再回顾下方法签名的概念:方法名称+参数类型+参数个数,组成一个唯一键,成为方法签名,这个唯一键是⑧能重复的。JVM就是通过这个唯一键决定调用那种重载的方法。
以下代码就是错误的重载方式,他们都有共同的特征,就是方法签名重复冲突了。
1 | public class EasyCoding { |
那么下面这几种情况,编译器是如何判断正确调用的呢,比如下面几种重载方法,第一处和第二处的结果是什么呢:
1 | public class EasyCoding { |
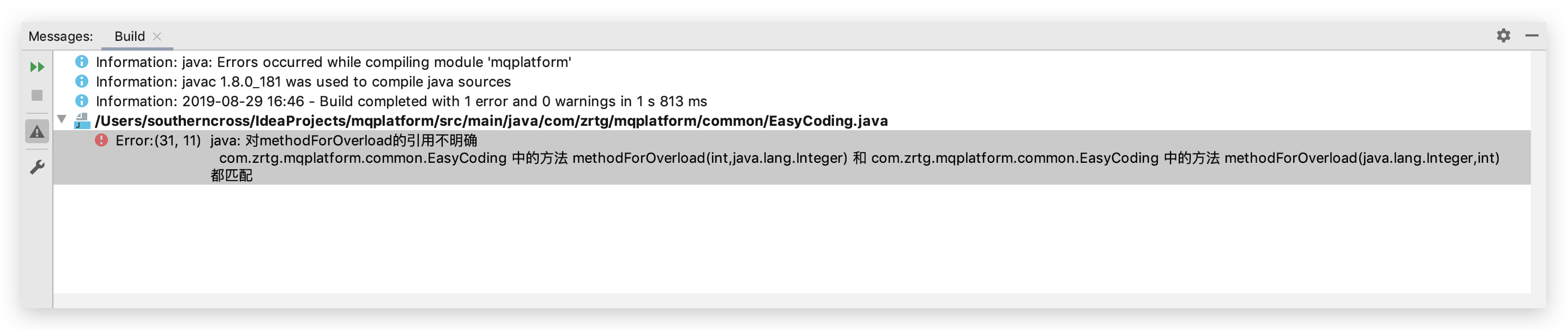
第一处答案是「int」,第二处的答案是「Integer…」。那么为什么ec.methodForOverload(996)方法编译器会匹配到methodForOverload(int arg)呢,而ec.methodForOverload()无参方法缺席的情况下却匹配到了可变参数methodForOverload(Integer... args)?
可变参数的个数其实是从0个到多个,所以首先它也会和其他方法抢夺匹配ec.methodForOverload(996),然而他的优先级是最低的,弟中弟嗷。但是在无参方法缺席的情况,只有他符合这一条件,所以ec.methodForOverload()无参方法自然匹配上。而int和Integer还有Object的较量中胜出的原因是不需要自动装箱,假如把int类型改成long类型,编译器一定也是Matchlong类型,而优于装箱的Interger。
但是如果是methodForOverload(null)这种情况则会调用参数为Integer的方法,Null可以匹配任何类对象,从最底层一次向上查找,会找到Integer和Integer...这两个参数方法,但是会报错,因为他们同时Match上了。
JVM在重载方法的顺序如下:
- 精确匹配。
- 如果是基本数据类型,自动转换成更大表示范围的基本类型。
- 通过自动拆箱和装箱。
- 通过子类向上转型继承路线依次匹配。
- 通过可变参数匹配。
我们程序猿心情不好的时候也会把气撒在编译器上,有时候,我们会不断挑战编译器的下限,比如这样:
1 | public class EasyCoding { |
此种方式就是完全在挑战编译器的底线了,虽然编译会通过,但是调用的时候一定会报错。
泛型
泛型也许是很多人相对陌生的领域,但是它⑧是多么神秘,本质是类型参数化,解决不确定具体对象类型的问题。Java在引入泛型之前,表示可变类型往往存在类型安全的风险,举个例子,微波炉最主要的功能是加热食物,而食物也有几十几百种可能,所以一般会像下面这样写业务设计:
1 | public class EasyCoding { |
这里的heat方法就是为了避免给每个类型的食物定义一个加热方法,但是只能采用“向上转型”的方式才能具备加热任意类型食物的能力。但是会让客户端困惑,因为对加热的内容不能正确区分,在取出时进行强制类型转换就会存在类型转换风险。而泛型就是为了解决这个而生。
泛型使用
泛型可以定义在类、接口、方法中,编译器通过识别尖括号和尖括号内的字母来解析泛型。现在一般约定俗成的符号有:
- E:代表Element,用于集合中的元素。
- T:代表the type of object,表示某个类。
- K:代表Key。
- V:代表Value,K和V用于键值对元素。
下面这段代码可以很好地说明泛型定义的概念:
1 | public class EasyCoding<T> { |
首先这段代码是完全可以通过编译的,可能没用过泛型的小伙伴会疑问为什么get()方法可以传入Integer和Long甚至是byte[]类型?而且返回的结果不应该是String类型吗?其实关键就在于<String, T, Object>这个泛型标识,String是我们常见的所熟知的包装类了,Object是所有类的父类,但是在泛型标识里,它就不是String和Object了,而是可以成为任意类型,属于完全未知的类型,入参的第一个参数如果是Integer类型,那么在方法体内的所有arg1就不是我们认知里的java.lang.String了,这个String就是相当于之前说明的T,Object也是一种T,仅仅只是一个代号。
当然我们平时编码不会也不要这样去定义泛型,确实会容易引发歧义和造成其他问题。所以我应该注意以下几点:
- 尖括号里的每个元素都指代一种位置类型。
<String>这里的String就不是我们认知上的java.lang.String了,仅仅只是个代号。包括类名后的<T>和get方法前的<T>是两个指代,互不影响。 - 尖括号的位置非常讲究,必须在类名之后或方法返回值之前。
- 泛型在定义处只具备执行Object方法的能力。所以
arg1和arg2只能调用Object类中的方法,比如toString()。 - 对于编码之后的字节码指令,其实没有这些花头花脑的方法签名,充分说明了泛型只是一种编码时的语法检查。
所以之前微波炉加热食物的例子可以用泛型这样改写:
1 | public class EasyCoding { |
避免使用Object作为输入和输出可以控制强制转换带来的风险。因为依据墨菲定律,只要这种风险存在,就一定会发生ClassCastException异常。
数据类型
基本数据类型
基本数据类型9种:int、short、long、float、double、char、boolean、byte、refvar,其中refvar是句柄,是面向对象中的引用变量,默认值为Null。详细如下表格:
| 类型名称 | 默认值 | 大小 | 最小值 | 最大值 | 包装类 | 缓存区域 |
|---|---|---|---|---|---|---|
| boolean | false | 1B | 0(flase) | 1(true) | Boolean | 无 |
| byte | (byte)0 | 1B | -128 | 127 | Byte | -128~127 |
| char | ‘\u0000’ | 2B | ‘\u0000’ | ‘\uFFFF’ | Character | (char)0~(char)127 |
| short | (short)0 | 2B | -2^15 | 2^15-1(32767) | Short | -128~127 |
| int | 0 | 4B | -2^31 | 2^31-1 | Integer | -128~127 |
| long | 0L | 8B | -2^63 | 2^63-1 | Long | -128~127 |
| float | 0.0f | 4B | 1.4e-45 | 3.4e+38 | Float | 无 |
| double | 0.0d | 8B | 4.9e-324 | 1.798e+308 | Double | 无 |
注意:其中缓存区间是个有意思的东西,估计很多人没有深究过,大厂面试很有可能就来这么一道题,所以接下来的包装类的内容要仔细看看哦~
对象分为三块存储区域:
- 对象头。对象头占用12B,其中包括:哈希码、GC标记、GC次数、同步锁标记、偏向锁持有者(反正👴⑧是很懂)。
- 实例数据。存储本类对象的实例成员变量和所有可见的父类成员变量。
- 对齐填充。
包装类型
包装类的存在是为了解决了基本数据类型无法做到的事情:泛型类型参数、序列化、类型转换、高频区间数据缓存。尤其是最后一个,因为除了Float和Double之外,其他包装类型都会缓存。拿Integer举例,缓存区间在-127~128,所以在这个区间的赋值,Integer对象会由IntegerCache.cache产生,就不会复用已有对象。因此,推荐所有包装类对象之间的比较,全都使用equals()方法。
源码如下:
1 | public static Integer valueOf(int i) { |
各个包装类的缓存区间:
- Boolean:使用静态final变量定义,valueOf()就是返回这两个静态值。
- Byte:表示范围是-128~127,全部缓存。
- Short:表示范围是-32768
32767,缓存范围是-128127。 - Charater:表示范围是0
65535,缓存范围是0127。 - Long:表示范围是[-2^63,2^63-1],缓存范围是-128~127。
- Integer:表示范围hi[-2^31,2^31-1]。
接下来我们看看如果不使用equals()方法去进行包装类的比较会出现什么情况
1 | public static void main(String[] args) { |
以上代码四处打印的结果是不是让人觉得都是true?
但是答案是第一处打印的结果是true和flase,第二处全是true,第三处也是true和flase,第四处全是true。
那么为什么System.out.println(i1 == i2);的结果是true,而System.out.println(i3 == i4);是flase呢?
该例很好地说明了Integer和Long只是缓存了-128~127之间的值,而大于或者小于区间的值没有被缓存,i3和i4是128,刚好超出了这个区间,下面的l3和l4同理。
当然我们也可以修改包装类的缓存范围,在VM options加入参数-XX:AutoBoxCacheMax=7777,即可设置最大缓存值为7777,那么以上代码的打印结果全为true。
在选择使用包装类和基本类型的时候,也不能完全按照心情,我们可以从以下几点来看:
- 所有的POJO类属性必须使用包装数据类型。
- RPC方法的返回值和参数必须使用包装数据类型。
- 所有的局部变量推荐使用基本数据类型。
字符串
字符串是从堆上分配而来,算是基本数据类型的小弟。主要是三种:String、StringBuilder、StringBuffer。
- String是只读字符串,典型的immutable对象,对它的任何改动,其实都是创建一个新对象,再把引用指向该对象。String对象赋值操作后,会在常量池中进行缓存,下次申请创建对象时,缓存中已经存在,则直接返回相应引用给调用者。
- StringBuffer可以在原对象上进行修改,是线程安全的。
- StringBuilder是非线程安全的,把多线程的锁的处理交给工程师(也就是宁👴)来处理,所以操作效率比较高。
线程安全的对象的产生一般是因为计算机的发展总是从单线程到多线程,从单机到分布式。
字符串的连接方式在循环体内非常不推荐使用String类型相加,而是应该使用StringBuilder的append方法。